
As I sat waiting for one of my Python programmes to complete, I thought – “Why not see what the people are thinking of Brexit?”
One way to do this would be to look at news articles and run some form of textual analysis. Now, while the theory is that the news suggests what the people think (given their need for high PR, traffic, etc), it’s not necessarily exactly what people think.
With that in mind, I figured it’ll be interesting to look at the comments within the articles, instead of the articles themselves.
Extracting the Data
I started slightly unconventionally, by manually extracting URLs for 7 BBC articles about Brexit. Of course, I could have programmed this and asked Python to extract it on its own, but I figured this is just a tiny little “afternoon pet project”. And given that I’m only working with 5-10 articles, it’s okay for me to get them manually.
I hear the “DRY” (don’t repeat yourself) proponents cringing at this. I hear you.
Importantly, it’s only the URLs that I collected manually; everything else was done programatically. In future, I’ll automate the URL extraction step, too.
Moving on though…
Here are the articles I selected:
- https://www.bbc.co.uk/news/uk-politics-49251257
- https://www.bbc.co.uk/news/uk-scotland-scotland-politics-49251511
- https://www.bbc.co.uk/news/uk-politics-49240809
- https://www.bbc.co.uk/news/uk-politics-49255061
- https://www.bbc.co.uk/news/business-49183324
- https://www.bbc.co.uk/news/uk-politics-49234603
- https://www.bbc.co.uk/news/uk-politics-49223319
These were the “usable” URLs on the first page of Google for the search term “bbc news brexit”, with the time criteria set to the “Past week” as at 7th August, 2019.
This simple “filter” meant that I essentially got the 7 most popular, and most recent articles about Brexit published by the BBC. That’s because Google would’ve prioritised the context (Brexit) by ranking the most relevant / popular articles highest, and the “Past week” filter meant that the articles are the most recent ones.
There were no comments available for these 2 articles:
- https://www.bbc.co.uk/news/uk-politics-49255061
- https://www.bbc.co.uk/news/uk-politics-49223319
Which brought down the number of articles to 5.
For each article, I extracted all the comments. There are 21,391 comments in total.
In addition to the comments, I also extracted:
- User ID (usernames),
- Upvote counts
- Downvote counts
Although the user IDs are publicly available / accessible, I do not disclose any names to protect their identities nevertheless.
Cleaning the Data
Following standard practice in dealing with text data, for each comment, I:
- Remove “stopwords” (i.e., all the common words; e.g., “the”, “is”, “a”, etc)
- Remove all symbols and numbers (e.g. %, $, *, etc)
Next, I “tokenize” (essentially, get all the words) each comment. Here are the top 10 most common words across all comments:
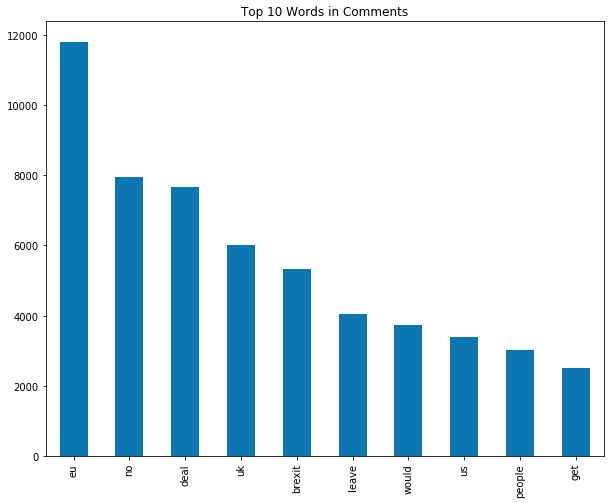
Notice the word “no”?
Strictly speaking, that shouldn’t be in there. Because that’s a “stopword”. I explicitly removed “no” from the list of stopwords to try and gain some sort of an insight on “no deal”.
Determining the “Sentiments”.
With the data cleaned and ready to go, I extracted 2 “dictionaries” (aka “lexicons”); one for “positive” words, and one for “negative” words.
I used the lexicons created by Loughran and McDonald. Strictly speaking, this might not be appropriate since the words in these lexicons are meant for Financial / Accounting data. Specifically, it’s meant for things like the annual reports companies publish.
So, while the word “liability” might sound negative to non-Accounting / non-Finance folks, it’s a “neutral” term for Finance / Accounting people.
It’s possible then, that the words in these dictionaries underrepresent the “true” level of sentiment.
To truly assess the Brexit sentiment, we’d ideally want a dictionary of “brexit related positive words”, and “brexit related negative words”.
But recall that this exercise was merely an “afternoon pet project”, and creating a dictionary from scratch requires time. A lot of time.
With the dictionaries in place, I proceed to estimate sentiments. This involves assessing how many words in each comment are “positive”, and how many are “negative”.
For each comment, I have a “positive” count, and a “negative” count.
Exploring the Sentiments
Full Sample
On average, comments tend to be 2.55 times more negative than positive.

Thanks to the “Upvotes” and “Downvotes” data, one could see that on average, comments are “upvoted” nearly twice as much as they are “downvoted”, with a mean (average) “upvote” count of 12.5 and a mean “downvote” count of 6.6
Top 10 Commentators
I thought it’d be interesting to see if the findings above are any different for the “top 10 commentators” (i.e., those that comment the most).
The most frequent commentator (who shall remain unnamed) wrote 157 comments in total, or just over twice as many comments as the 10th most frequent commentator (who wrote 74 comments).
In total, the Top 10 commentators wrote 1,041 comments – just under 5% of the total number of comments.
On average, the Top 10 commentators’ comments were more negative (mean value = 1.1) than positive (mean value = 0.46).
In other words, the Top 10 commentators’ comments tend to be more negative relative to the average commentator. And also more positive, relative to the average commentator.
However, as far as the ratio of positive : negative goes, the Top 10 commentators were a tad bit more positive (2.37 vs. 2.55 above).
When it comes to the “upvotes” vs. “downvotes”, we see something quite interesting. They tend to be “upvoted” just over three times as much as they’re “downvoted” (compared to a ratio of 2:1 for the average commentator).
Leave vs. Remain
Last, but certainly not the least, one can’t do a “Brexit” related post without comparing “leave” vs. “remain” (sadly).
The frequency of the word “leave” was approximately 2.4x (strictly, 2.36x) higher than the word “remain”.
That being said, thankfully, the conversations are about a whole lot more than just “leave” vs “remain”. Both words only make up just 1.17% of the 490,767 total words across 21,391 comments.
Got an interesting question in mind? Imagine what we could do together, for your business.
This “project” took me a few hours one afternoon. That included:
- Ideation: “What do people think about Brexit?”
- Data strategising: Where can I get reliable, credible data, quickly?
- Data “wrangling”: How do I process and setup the data to help me gain valuable insights efficiently?
- Data analytics: How can I use the data to answer interesting questions, reliably?
- Communicating key findings: Sharing the answers (my second favourite part of Data Science)!
Of course, more time would allow for better hypothesis design, collecting a richer dataset, creating better models, and conducting strong robustness tests.
Discuss Your Data Science Project With Me
Appendix (technical stuff)
Technical stack used:
Python, specifically:
- pandas (general data wrangling and analytics),
- nltk (stopwords, tokenizing),
- re (parsing comments), and
- scipy (for testing the (unreported) statistical differences of positive vs. negative sentiments).
For the record, the difference between positive an negative scores is statistically significant (p ≈ 0)
Sample:
- Articles: 5
- Total number of comments: 21,391
- Total number of commentators (users): 5,498
- Total number of words (excluding stopwords*): 490,767
* the word “no” was excluded from the list of stopwords to explore “no deal”.
The sample is unlikely to be representative of the entire UK population. Although the BBC is the ‘national’ broadcaster, not everyone reads the BBC – and not everyone comments, obviously. Furthermore, while the number of comments is high, the total number of articles is minuscule. A significantly greater, richer sample would be required to make any meaningfully generalisable comments.
Feature image uses text from the comments. Image created from https://www.wordclouds.com/
Leave a Reply